基础知识
基础字符匹配
- 直接匹配字符本身: 例如
abc匹配字符串abc - 特殊字符(如果想匹配这些字符本身,需要在前面加 \(转义字符)):
.、^、$、*、+、?、{}、[]、|、()、\: 如果想匹配这些字符本身,需要在前面加 \(转义字符)
元字符含义
.:匹配任意单个字符(除了换行符)。 例如:a.b可匹配 “aab”、“acb” 等。^:匹配字符串的开始。 例如:^abc只能匹配以 “abc” 开头的字符串。$:匹配字符串的结束。 例如:abc$只能匹配以 “abc” 结尾的字符串。*:匹配前一个字符零次或多次。 例如:ab*可匹配 “a”、“ab”、“abb” 等。+:匹配前一个字符一次或多次。 例如:ab+可匹配 “ab”、“abb” 等,但不能匹配 “a”。?:匹配前一个字符零次或一次(非贪婪)。 例如:ab?可匹配 “a” 或 “ab”。{}:指定匹配次数。 例如:a{2,4}可匹配 “aa”、“aaa” 或 “aaaa”。{n}:匹配前一个字符 n 次。{n,}:匹配前一个字符至少 n 次。{n,m}:匹配前一个字符至少 n 次,至多 m 次。
\: 转义特殊字符。例如:\\匹配反斜杠,\.匹配点号
字符集和预定义字符
[abc]:匹配方括号中的任一字符(a、b 或 c)。 例如:[aeiou]匹配任一元音字母。[^abc]:匹配不在括号中的任意字符。 例如:[^0-9]匹配任意非数字字符。[a-z]:匹配从 a 到 z 的任意小写字母(范围匹配)。- 预定义字符类
\d:匹配任意数字(等价于[0-9])。\D:匹配任意非数字字符。\w:匹配任意字母、数字或下划线(等价于[a-zA-Z0-9_])。\W:匹配任意非字母、数字或下划线字符。\s:匹配任意空白字符(空格、制表符等)。\S:匹配任意非空白字符。
分组和捕获
():定义子表达式(分组),并捕获匹配的内容。 例如:(abc)+匹配 “abc”、“abcabc”。|:表示 “或”。 例如:abc|def匹配 “abc” 或 “def”。
零宽断言
- 正向前瞻:
(?=...)例如:a(?=b)匹配 “a”,仅当它后面是 “b”。 - 负向前瞻:
(?!...)例如:a(?!b)匹配 “a”,仅当它后面不是 “b”。 - 正向后瞻:
(?<=...)例如:(?<=b)a匹配 “a”,仅当它前面是 “b”。 - 负向后瞻:
(?<!...)例如:(?<!b)a匹配 “a”,仅当它前面不是 “b”。
其他
- 默认正则是 贪婪模式,尽可能多地匹配。
- 在量词后加
?使其变为 懒惰模式,尽可能少地匹配。 例如:a.*b匹配 “a…b” 整段,而a.*?b只匹配最短的 “a…b”。 i: 忽略大小写, 这个标志会使得正则表达式在匹配时忽略字母的大小写。例如,/a/i 可以匹配 ‘a’ 或 ‘A’g: 全局匹配, 这个标志使正则表达式进行全局匹配,而不仅仅是匹配第一个符合的内容
应用示例
- 匹配电子邮件地址:[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}
- 匹配手机号(中国):1[3-9]\d{9}
- 匹配日期:\d{4}-\d{2}-\d{2}
JS RegExp 相关 API
RegExp.prototype.exec()
exec(str): 如果匹配成功,返回一个数组,数组的第一个元素是匹配的完整字符串,后续元素是捕获组的内容;如果没有匹配到,返回 null
/(\d+)-(\d+)/.exec('The date is 2023-10-15') // ['2023-10', '2023', '10', index: 12, input: 'The date is 2023-10-15', groups: undefined]RegExp.prototype.test()
test(str): 如果正则表达式和字符串之间匹配 str 的否则为 false
/abc/i.test('ABC is here') // trueRegExp.prototype.toString()
RegExp.prototype[Symbol.match]()
- 如果正则表达式没有使用全局标志 g,match() 方法会返回一个数组,数组的第一个元素是匹配到的完整字符串,后续元素是捕获组(如果有的话),此外该数组还包含一些额外的属性,如 index 表示匹配结果在原字符串中的起始位置,input 表示原字符串
- 如果正则表达式使用了全局标志 g,match() 方法会返回一个包含所有匹配结果的数组,但不包含捕获组信息。如果没有匹配到任何结果,则返回 null。
"Hello, hello!".match(/hello/i) // ['Hello', index: 0, input: 'Hello, hello!', groups: undefined ]
"Hello, hello!".match(/hello/gi) // [ 'Hello', 'hello' ]RegExp.prototype[Symbol.matchAll]()
matchAll() 方法返回一个迭代器对象,该迭代器中的每个元素都是一个数组,数组的格式与 match() 方法在不使用全局标志 g 时返回的数组格式相同,包含匹配到的完整字符串、捕获组信息以及 index 和 input 属性。如果没有匹配到任何结果,迭代器为空。
"Hello, hello!".matchAll(/hello/gi)]
// [ 'Hello', index: 0, input: 'Hello, hello!', groups: undefined ]
// [ 'hello', index: 7, input: 'Hello, hello!', groups: undefined ]RegExp.prototype[Symbol.replace](pattern, replacement)
pattern: 可以是一个字符串或者一个正则表达式。如果是字符串,它只会替换匹配到的第一个子字符串;如果是正则表达式,它会根据正则表达式的规则进行匹配替换,并且如果正则表达式带有 g 全局标志,则会替换所有匹配的子字符串
replacement: 可以是一个字符串或者一个函数。如果是字符串,它会替换掉匹配到的内容;如果是函数,该函数会在每次匹配时被调用,函数的返回值将作为替换的内容
"Hello, hello!".replace(/hello/i, '你好') // '你好, hello!'
"Hello, hello!".replace(/hello/gi, (v) => `${v}`.toUpperCase()) // 'HELLO, HELLO!'RegExp.prototype[Symbol.replaceAll](pattern, replacement)
pattern: 可以是一个字符串或者一个正则表达式。如果是正则表达式,必须带有 g 全局标志,否则会抛出错误
replacement: 可以是一个字符串或者一个函数,作用和 replace() 方法的第二个参数相同
"Hello, hello!".replaceAll(/hello/gi, '你好') // '你好, 你好!'RegExp.prototype[Symbol.search](regexp)
regexp: 正则表达式对象或具有 Symbol.search 方法的任何对象, 如果 regexp 不是 RegExp 对象并且没有 Symbol.search 方法,则使用 new RegExp(regexp) 将其隐式转换为 RegExp
返回值: 执行正则表达式和此字符串之间的匹配项的搜索,返回字符串中第一个匹配项的索引
'2020-01-02'.search(/-/g) // 4RegExp.prototype[Symbol.split]()
性能问题
当正则表达式包含大量的可选分支、嵌套的分组、重复字符(如 *、+、? 等)以及复杂的字符类时,其匹配过程会变得非常复杂,从而导致性能下降。回溯是正则表达式匹配过程中的一种机制,当匹配失败时,正则引擎会回溯到之前的状态,尝试其他可能的匹配路径。
例如过多的回溯会导致性能急剧下降。例如,正则表达式 /.+(\d+)+/ 匹配字符串 abc123def456 时,(.+) 会尽可能多地匹配字符,然后 (\d+)+ 尝试匹配数字。如果匹配失败,正则引擎会回溯 (.+) 匹配的字符,重新尝试 (\d+)+ 的匹配,这个过程可能会重复多次,消耗大量时间。这种情况下,可以考虑使用其他更高效的数据处理方法,如基于字符串分割。
/\s*,\s*/.test('\t'.repeat(N) + '\x00,') 执行时间变化图
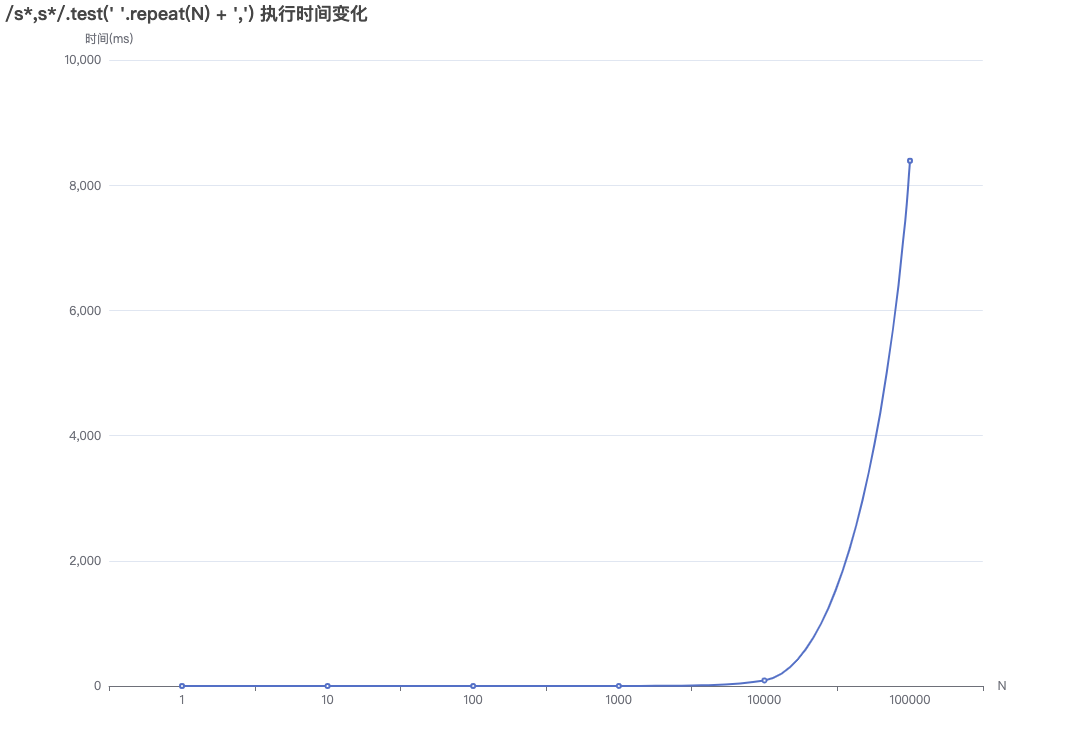
你可以在https://devina.io/redos-checker 检查正则表达式是否存在潜在的拒绝服务漏洞